Updates Sept 2
PGrid
- added an affiliate disclosure message to each page as ebay emailed me about it being a requirement
- missed another deal i could have posted to ozbargain. this time due to the card being incorrectly classified as a 4070 when it was a 4070 super.
- automated to run ebay and amazon indexing every day. this is the initial searching for new gpu listings, doing an initial ai classification and putting them in an unverified gpu table to be manually validated. used to manually run this once every few days due to slightly higher ai cost.
- removed myself from doing manual validation on ai classified cards for the most popular cards. now after ebay and amazon get indexed, claude will do the validation on the ai classification. I will get an email after claude does the validation so i can double check. hopefully wont miss opportunities to post to ozbargain now.
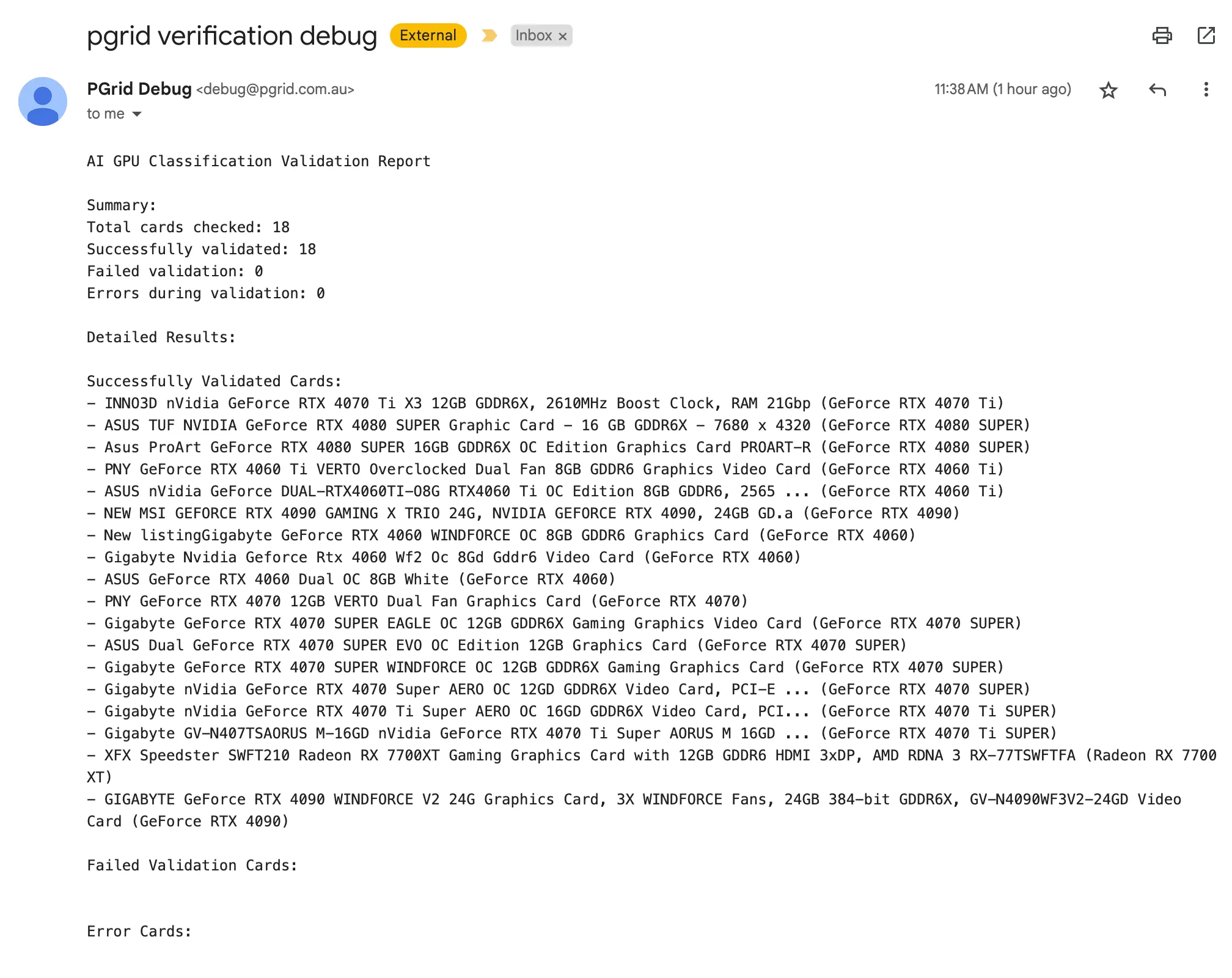
- The gpu from the ozbargain deal was a 4070 super incorrectly classified as a 4070. I went to fix it and accidentally classified it as a 4080 super causing a few email alerts to incorrectly go out. had to run this code a few times to say sorry.

- first pgrid link found in the wild from a comment in ozbargain

- added scorptec scraper. lots of issues with this, mainly from them using cloudflare to block scrapers. Tried a few different things, what ended up working was using a puppeteer library called puppeteer-real-browser that has been configured to hide things that cloudflare fingerprints to detect bots. But once that was going locally, it was some more work getting it to work in the worker docker image as that was built for playwright. managed to get puppeteer to use the chrome installed by playwright through env vars. once deployed there was still a mystery issue where the browser would disconnect randomly.

- that ended up being fixed by using a puppeteer/browsers utility cli to download current chrome stable and use that with puppeteer. so the worker image now has both playwright and puppeteer. and the puppeteer chrome doesnt work on the ARM servers.
- made scraping a bit more efficient. before there would be one run through a site to find and add urls to then do ai classification and verification and a separate run to get prices. but they usually call the same scraper function which goes through all pages of gpus for a given site. so combined the two functions of finding gpu urls and getting prices. theres still an inefficiency that the ai classification of urls happens in a separate job.
- added a hidden field to the db for gpu chips so i can hide old and out of production gpus that some stores still stock for some reason
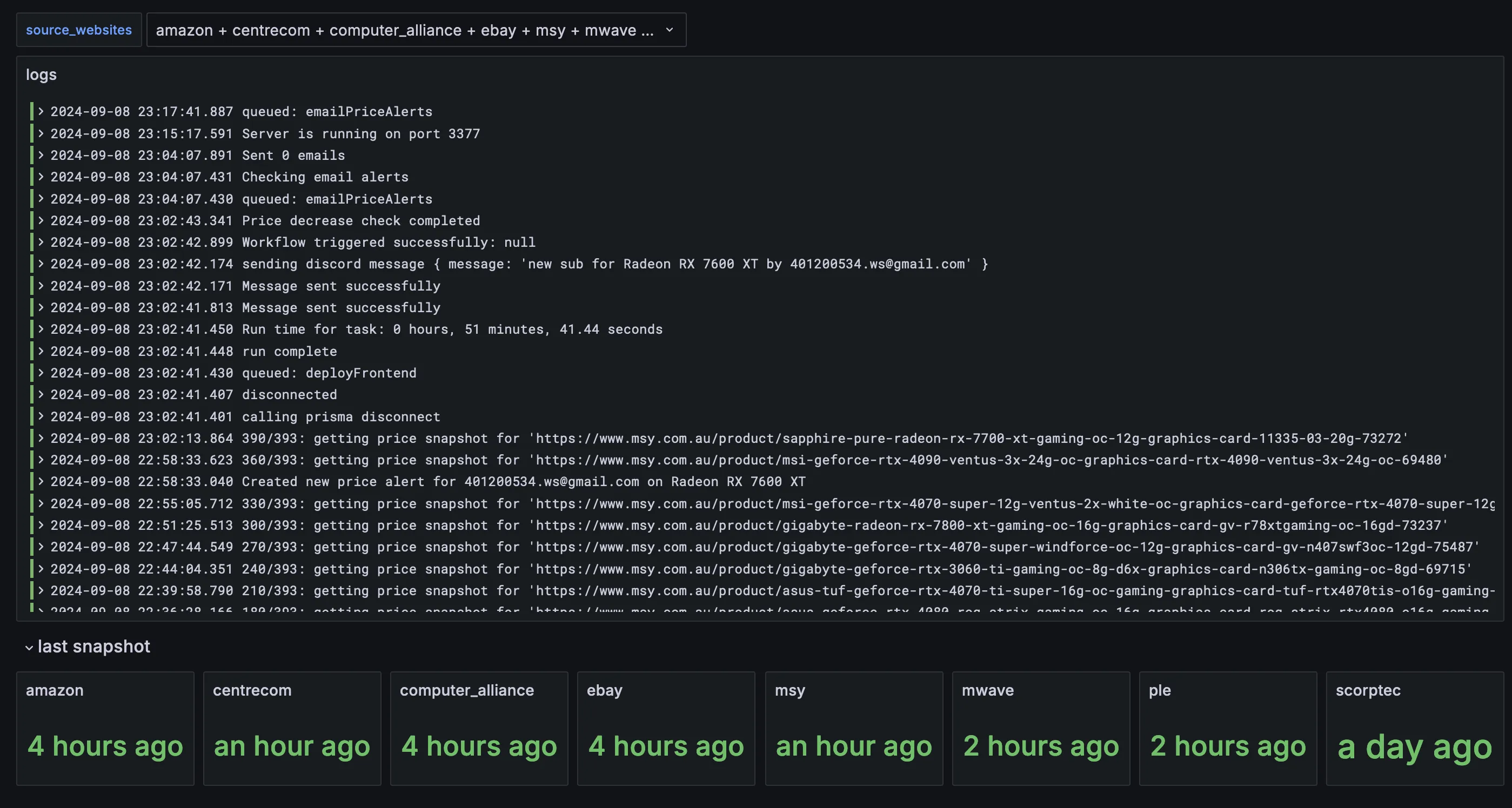
- playing around with open telemetry -> influxdb to show logs in grafana. wanting to split workers between a few servers and want a central place to view logs and metrics. got initial logs showing but terrible format to view
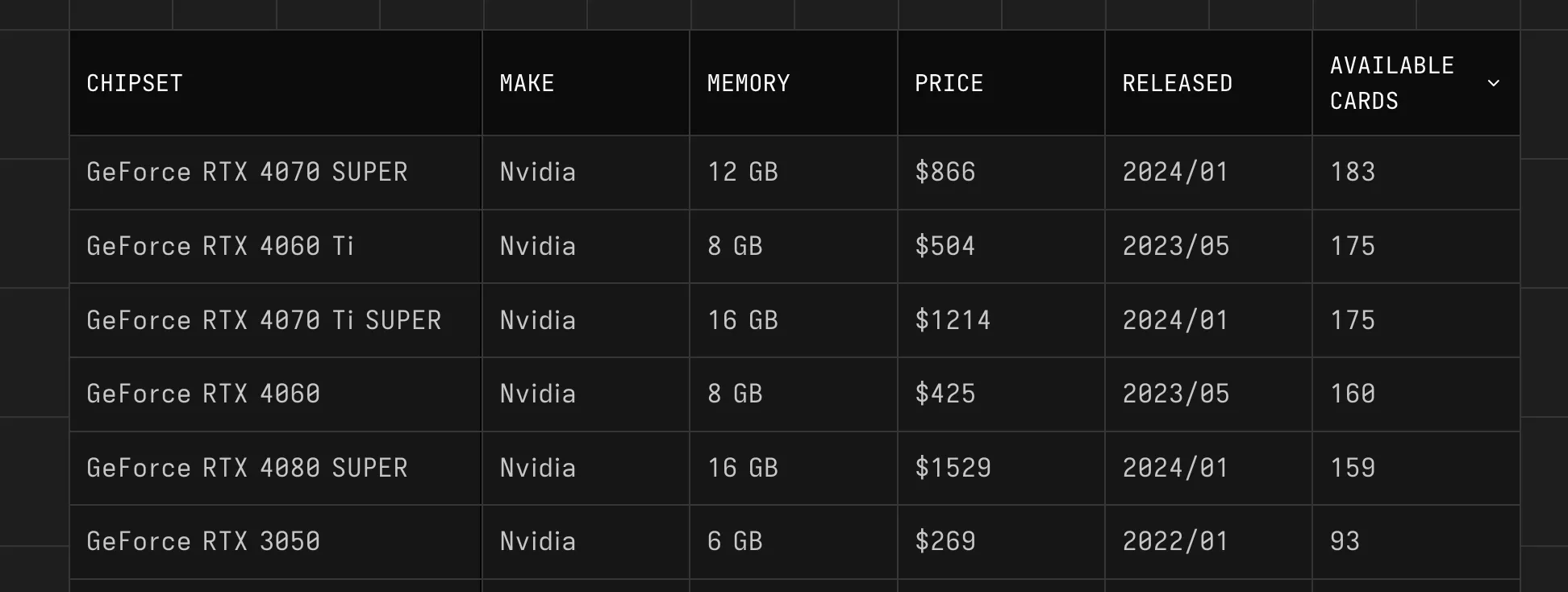
- added number of available cards as a new column on main table. Think it can be useful as a metric of popularity for those unfamiliar with gpus. also useful for me for debugging
- little refactoring done to add a shared query between frontend/workers to reduce tech debt. required adding shared code to frontend docker image
- been working on a grafana dashboard to make sure scrapers are reliable. this is what it looked like by the end of the week