Updates Sept 9
PGrid
- One of the gpus (RX 6700 XT) no longer had any available cards for sale from any of the sources and this resulted in it no longer being created as a page but there were still some other pages linking to it resulting in 404s. Ended up recreating all of the AI gpu product descriptions. Updated the prompt to make it stop using common ai words like ‘albeit’, and made the ai prefer new cards when suggesting the alternative gpus.
- Started working on being able to distribute getting single page price snapshots. Before, a single worker would iterate through all pages for ebay one at a time. but now i added a few workers, i have a new job type where its just one url to get a snapshot for. Advantage is faster distributed scraping but at the moment not sure how to tell when scraping a set of ebay urls has finished so further tasks like redeploying frontend or doing price check emails can be done.
- Debugging ebay scraping failure. for some reason the x server sometimes fully fails on a docker container which means any time a new browser tries to run it fails. this required a full container restart. Upgraded playwright versions in hopes this would be fixed but not sure.
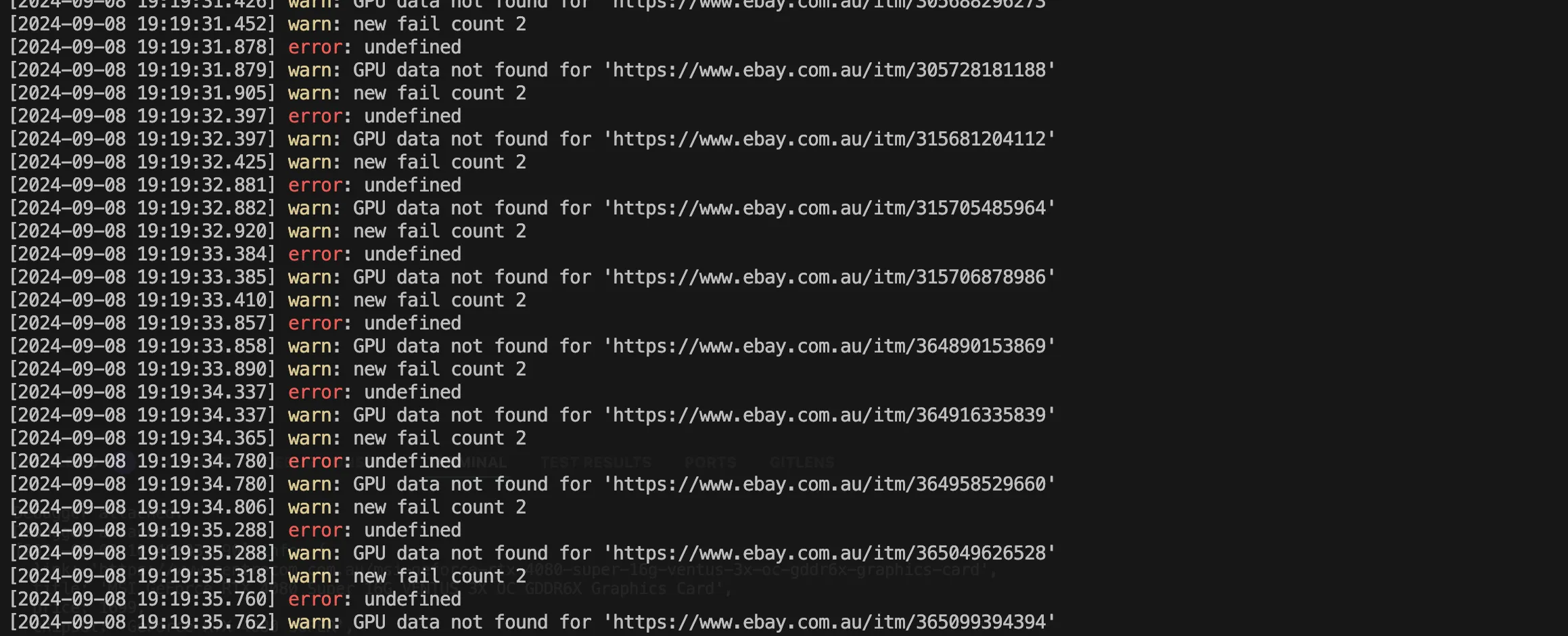
- Added a little home made automation to run workers on servers through ssh. before i manually sshed/tmuxed into servers to build/start worker containers. now i have a little makefile and script that does it for me. this is 2 parts at the moment. one script which adds a row in a table that each worker looks for, if there is a new row in that table it will shut down after it has completed its current task. and a second script which uses ssh and then runs a typescript file using bun to check if the worker docker container is running or not and runs it in tmux.
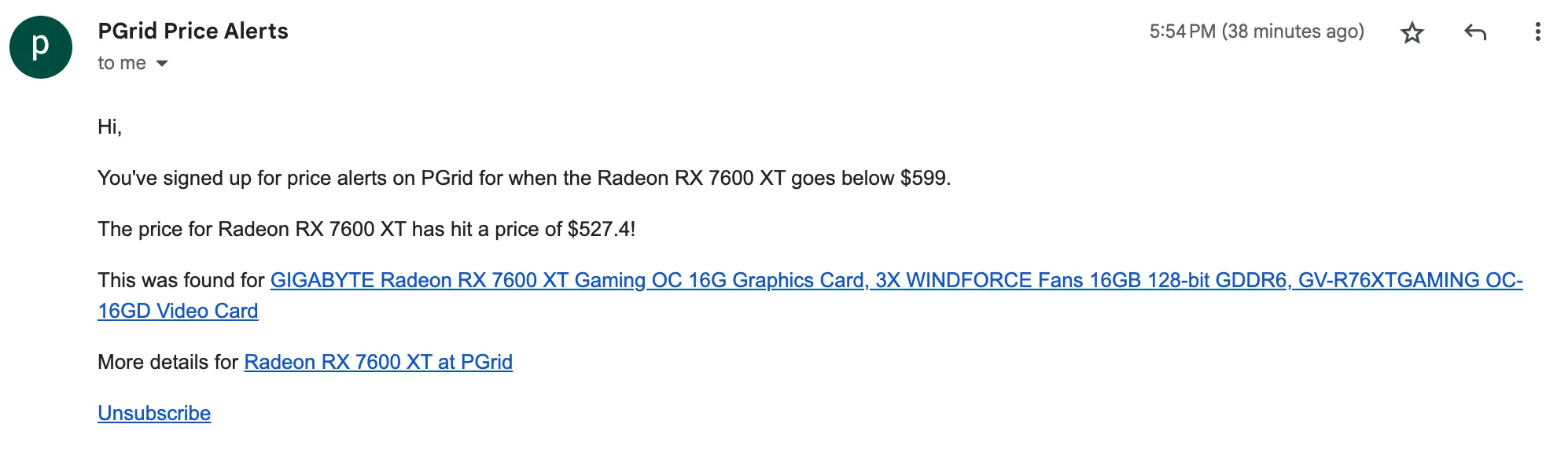
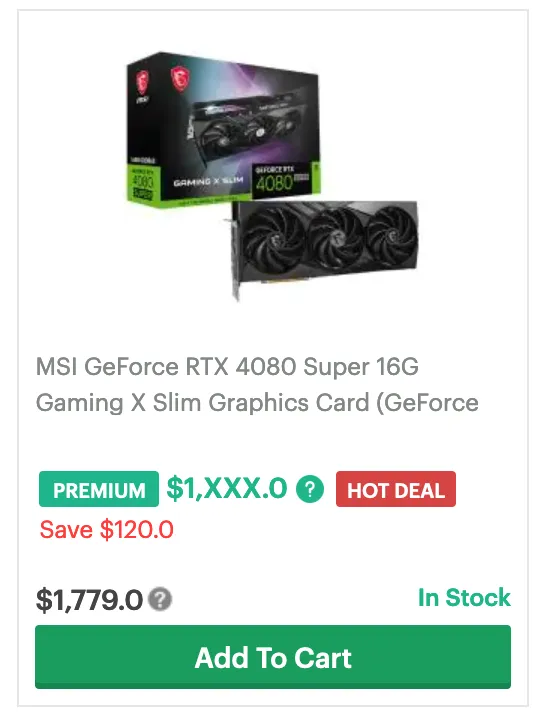
- Updated the email price alert email to include a direct link to the product that caused the price alert to happen. Includes affiliate links.
- Updated the msy scraper to work with bulk price snapshotting. now only ebay and centrecom scrapers work by visiting each gpu page individually. this is because they have coupon codes inside those pages so can’t be converted into using listing pages for scraping. Amazon is partially using search result pages and then visiting individual pages for those gpus that dont show up in search results
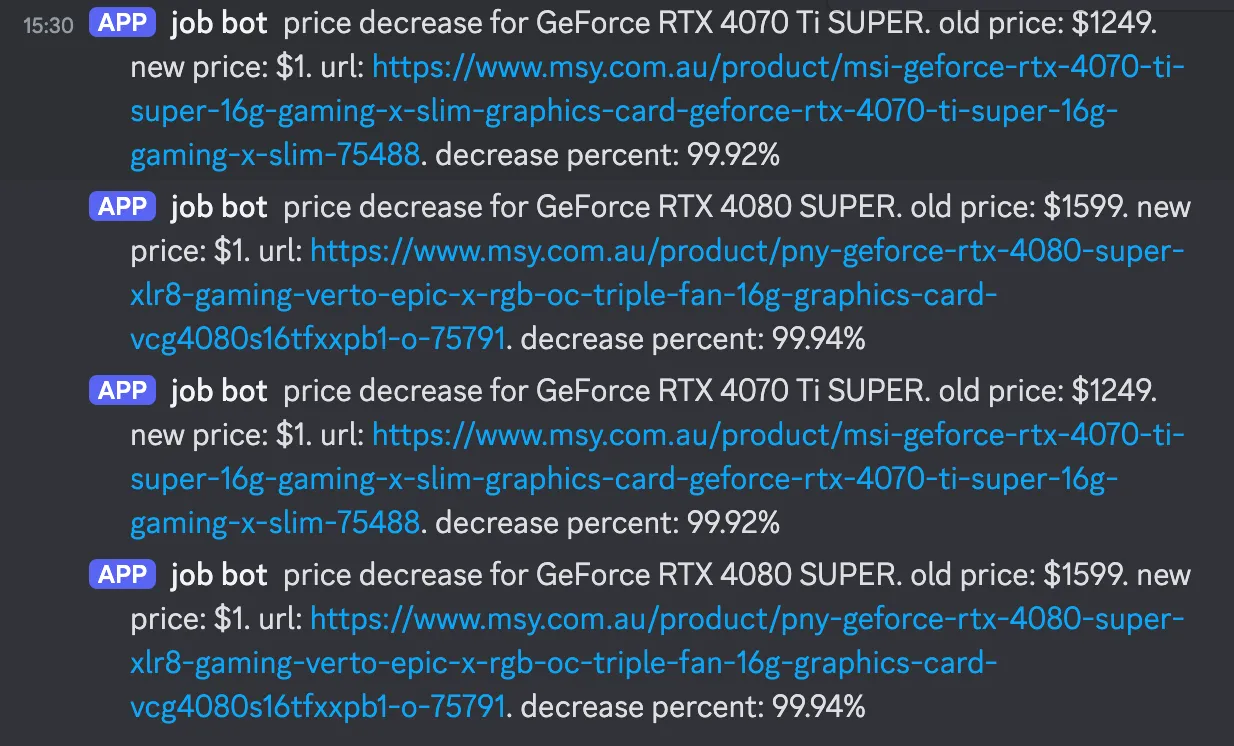
- That updated msy scraper ended up incorrectly parsing some prices. My price decrease job sent me a few sus discord messages and thanks to the worker automation i just added, was able to stop all workers so email alerts didn’t go out.
- Updated the worker automation to be configurable with an array of tasks to do for each host. ended up being a bit frustrating to implemented
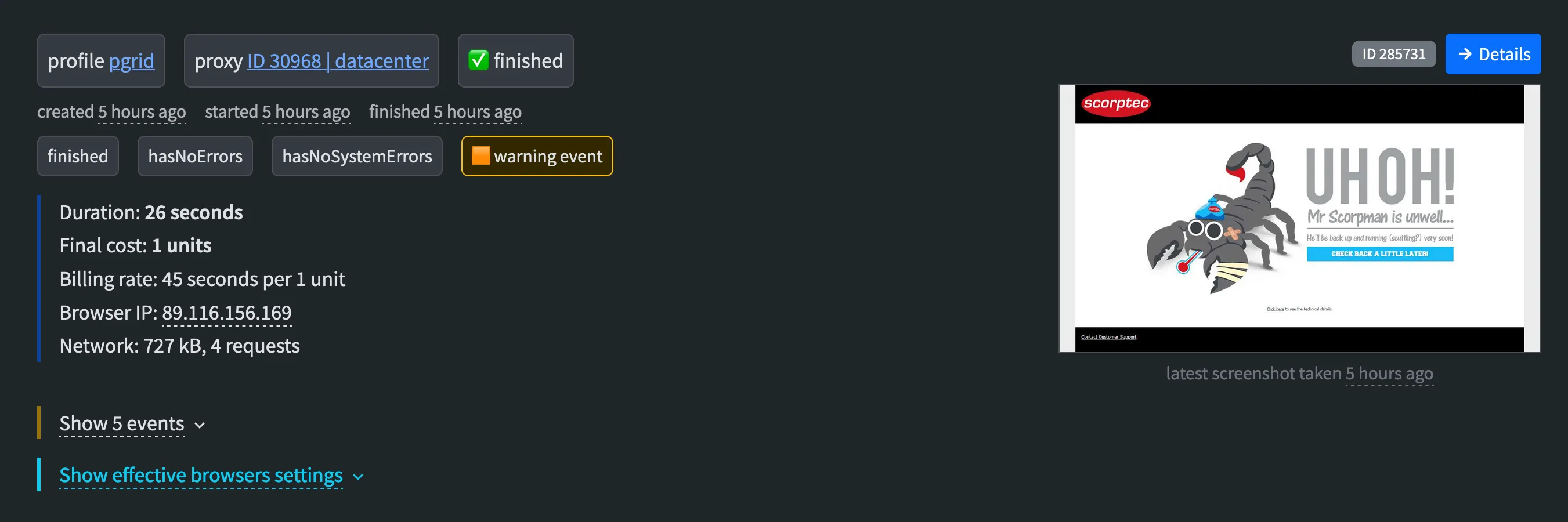
- Was having issues running the scorptec scraper in docker, so have been running it manually once or twice a day from my laptop. Started using a product called rebrowser.net as its a simple swap with puppeteer args to use. Unsure what rebrowser pricing is which is annoying. I have a month of credit to trail them. Product seems cool though, seeing screenshots of the scraping. After a few failed runs turns out that the proxy rebrowser was using might be getting blocked showing a error page when scorptec works fine visiting manually. fucking scraping.
- Added more metrics to track what each worker is doing so i can have a timeline in grafana. It works by sending the current task name every 10 seconds. Theres a bug where once it starts a task, it sends both the task name and
idle at the same time. I spent almost 2 days trying to fix this bug which is super dumb and a big waste of time but it seems like a super simple thing to not work. 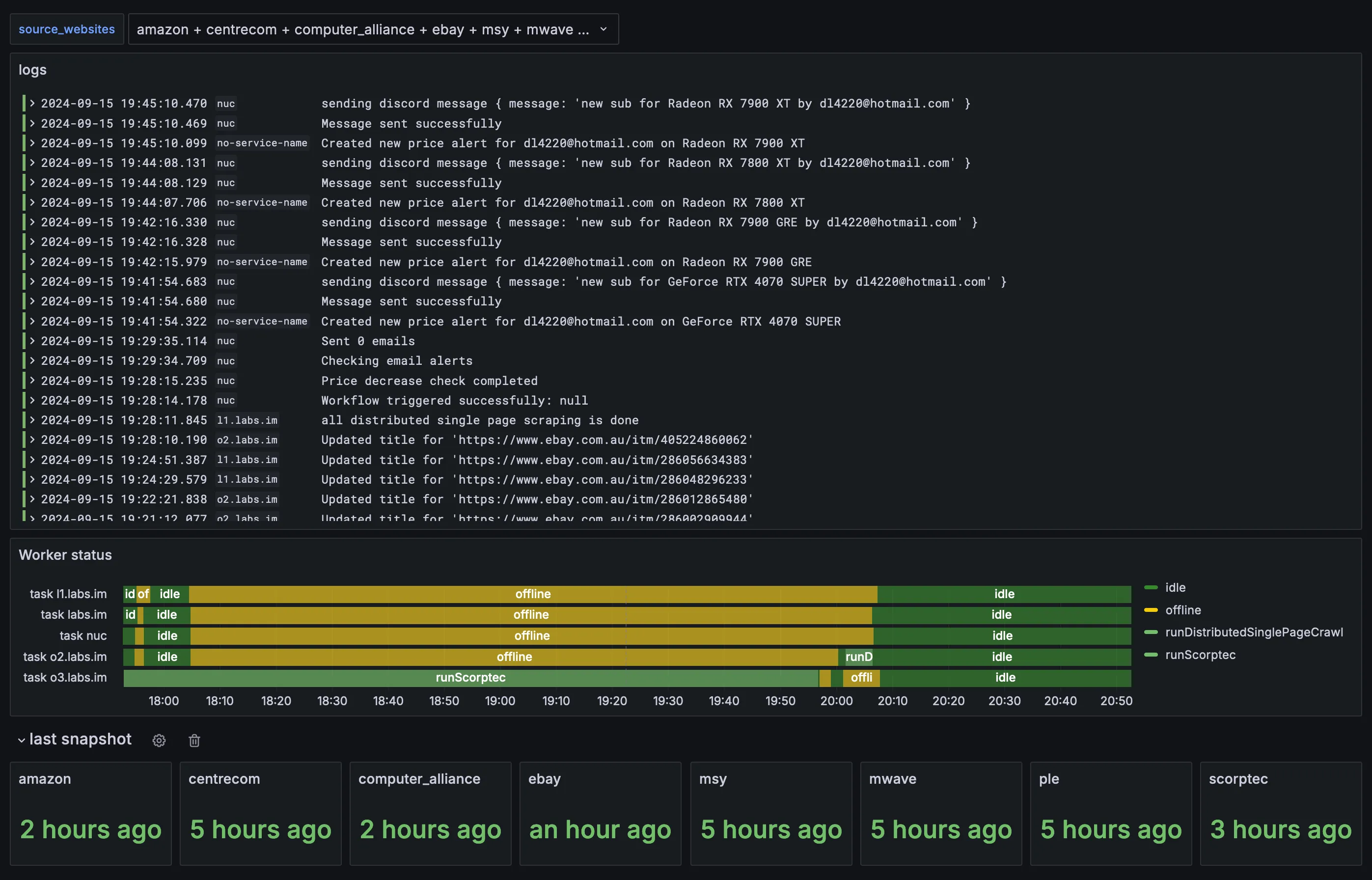
- Added a new schema for expand from gpus into other products but not nearly enough work done on this as I wanted.