Updates Dec 2
PGrid
- Previously got distributed ebay generic search working but it was an initial implementation that only worked sequentially (search -> visit individual pages from search results -> visit existing classified pages missing from search results). Updated that to run distributed across multiple workers so that one worker would do a search and update the database. The
visit pages missing from search results part ended up being a bit annoying to implement since I didn’t want to add shared state between workers but needed to know when the search part was completed.
- fixing ebay bugs
- Initial ebay scraping for cpus resulting in a lot of unclassified items.
before classification:
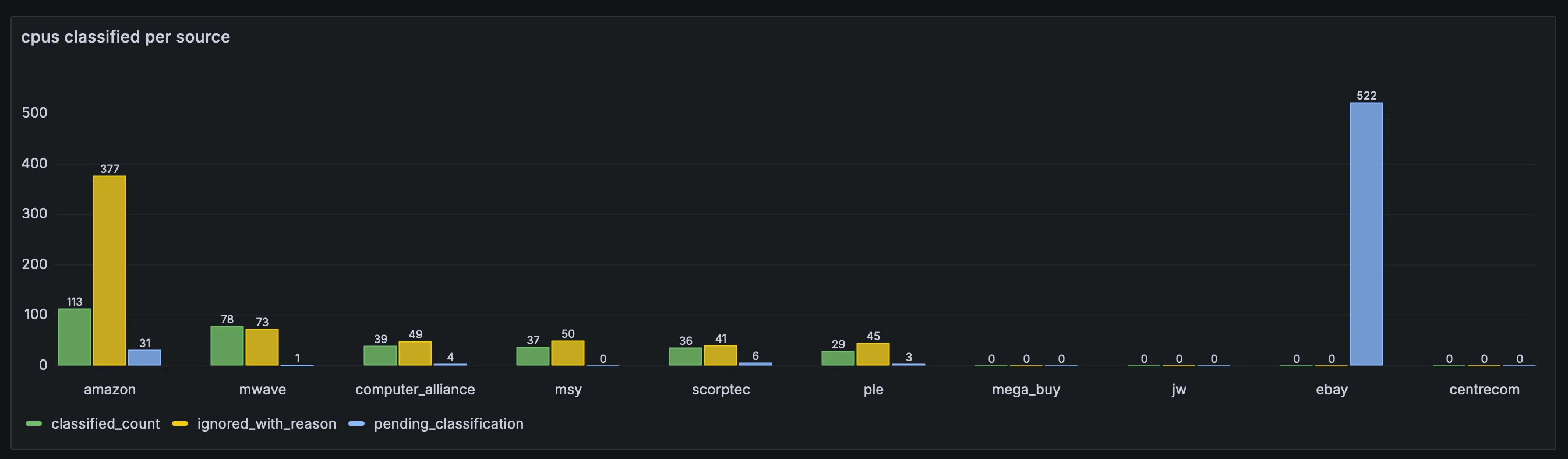 after classification:
after classification: 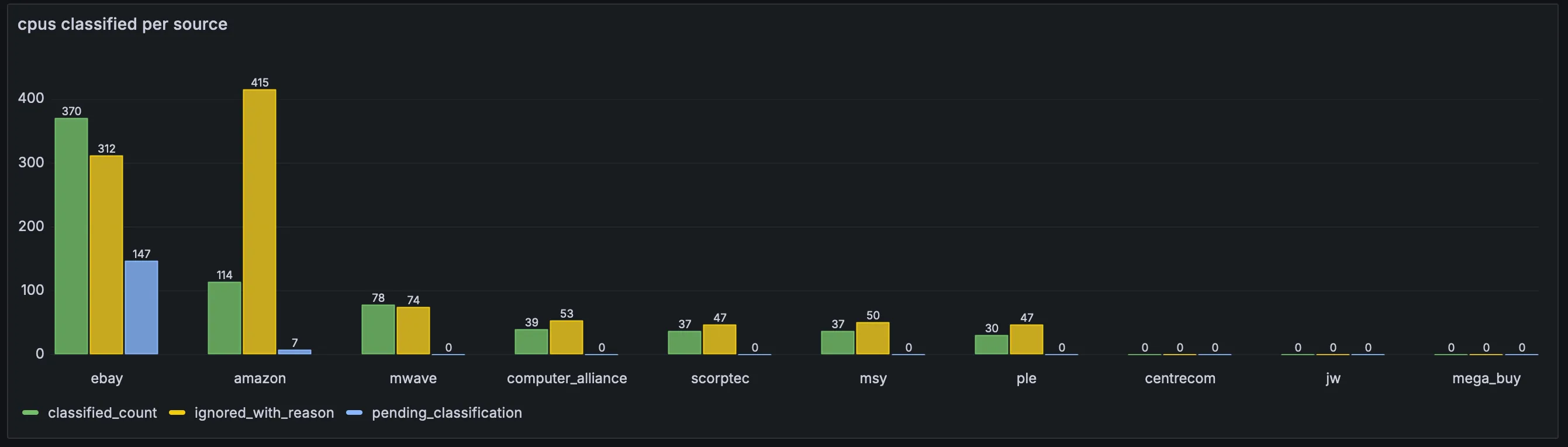
- Rewrote my discord price alert notification job which sends me a notification if there is a price decrease for gpus over 5% to use shared gpu queries instead of its own custom one. From this found a bug where it incorrectly thought there were price decreases. From that I found that ebay scraping doesn’t always save coupon discounts. This went undetected since email price alerts only trigger when a price is found below a specific threshold and price history plots only use the cheapest prices for each card over a whole day so even there were some missing coupon discounts as long as it was sometimes saving discounts the bug wasn’t noticeable.
- Updated generic item price snapshot deduplication. Only deduplicates exactly consecutive duplicate price snapshots and keeps duplicate snapshots that cross days in brisbane timezone.
- Added an Initial classifier using two models to come to consensus to ignore classifying items. This gets used as a filter before running items for classification and has high level of accuracy and is cheap using 2 cheap models.
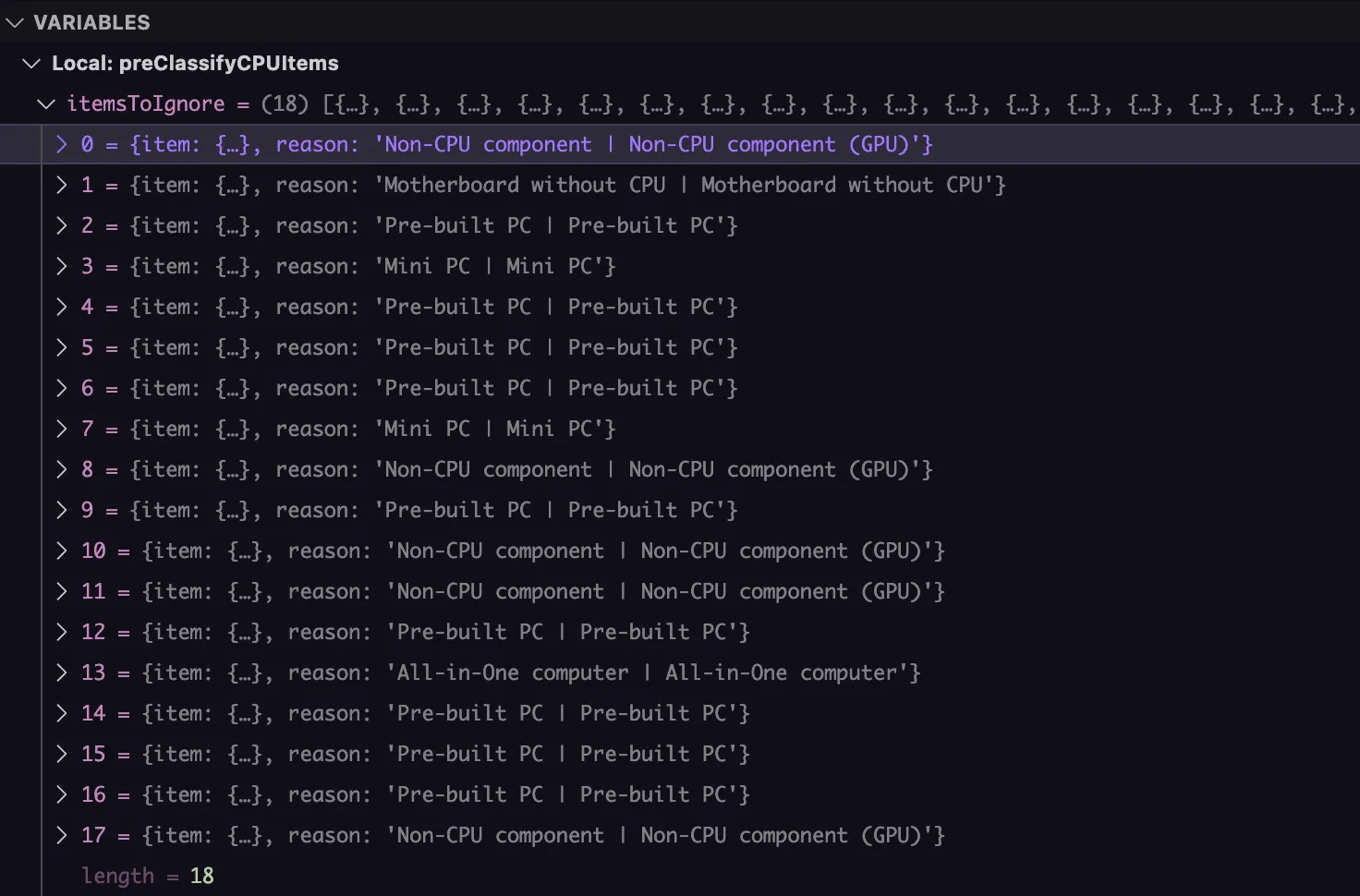
- Ran classification of 500+ ebay listings using new classification pipeline. Manually reviewed each classification, fixing incorrect classifications and updating prompts to handle issues.
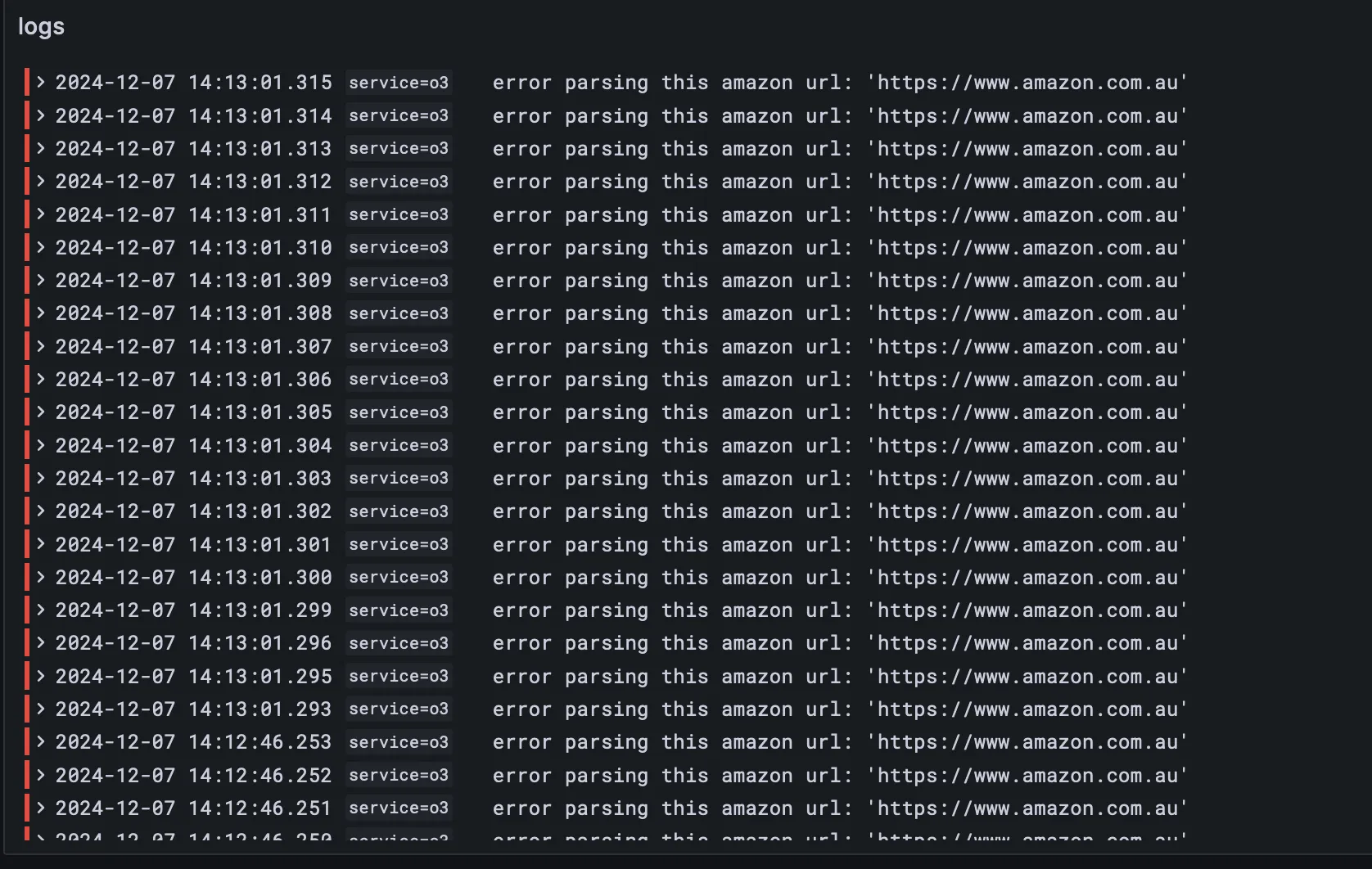
- On saturday looked at logs and all amazon search based scraping was erroring out. For gpu scraping, if it cant find items through using search it will fall back to scraping individual amazon urls which still worked. But turns out they modified their html slightly and it broke my search scraper. Scrapers are quite fragile. Looked at adding Grafana alerting but UI was complicated and didn’t bother.
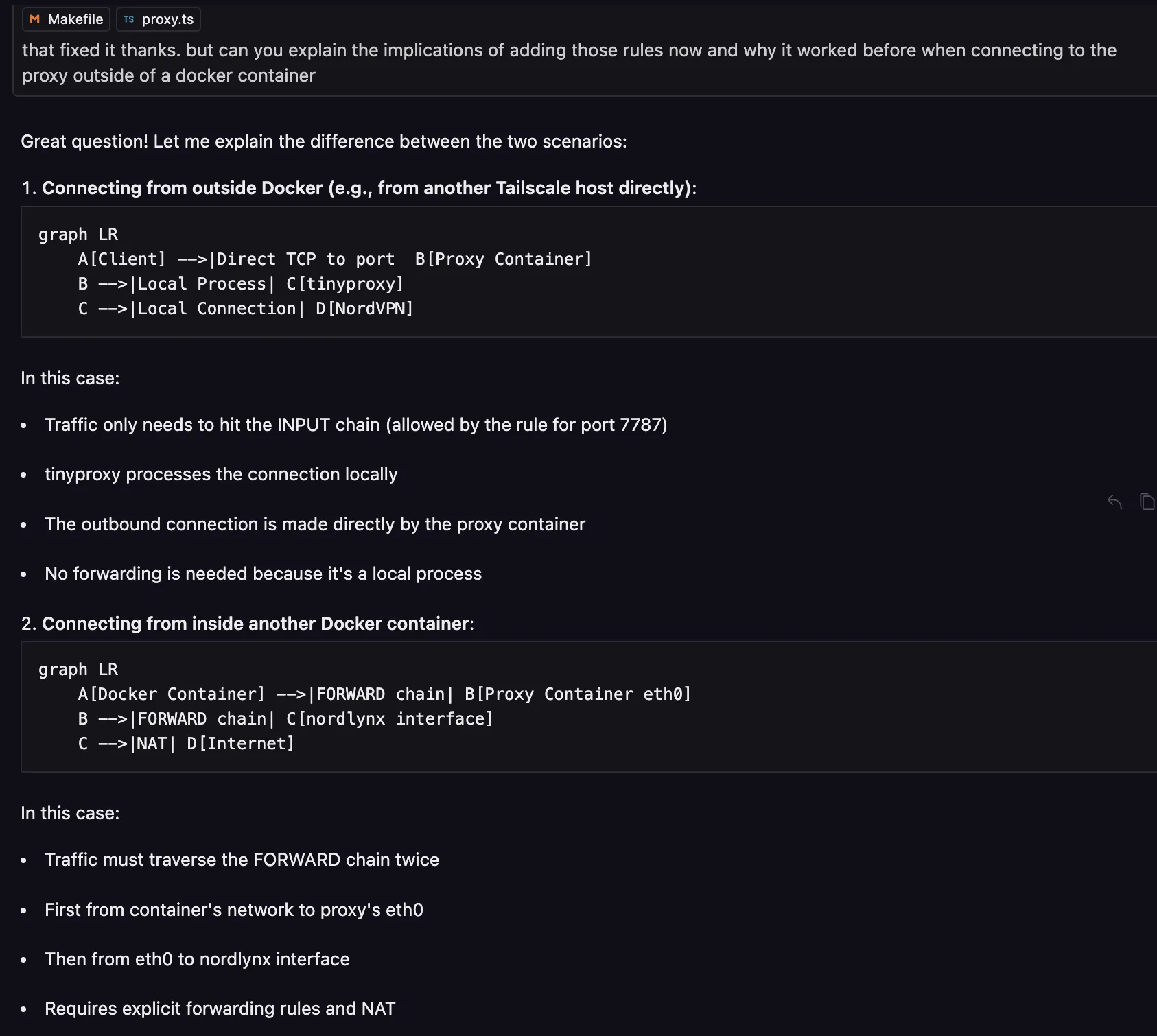
- Created a new service which runs a http proxy in a docker container that is also connected to nordvpn. Will allow switching IP address easily for scrapers, will allow multiple workers to run on the same server as I currently limit it to 1 worker per server to reduce traffic from the same IP address. Will also allow to scrape international versions of amazon and ebay easier. Found that most nordvpn IPs tend to have better reputation than some VPS and paid proxies that I have used.
- While initial dockerfile for the proxy was kinda simple, ran into issues when using that proxy from other worker containers even though local testing worked.
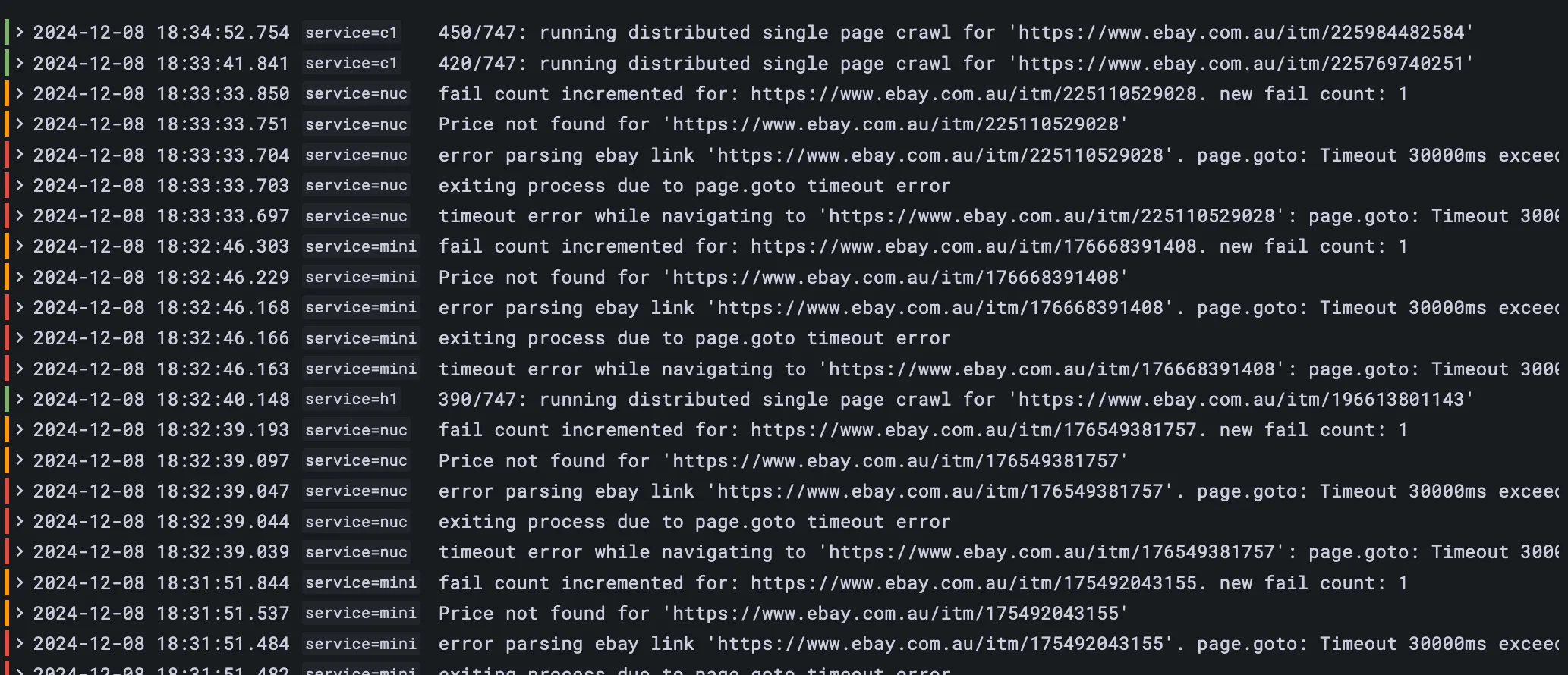
- After hours debugging by myself and with the help of ai, found it was an iptables networking issue from rules setup by nordvpn. Probably wouldn’t have been able to solve by myself.