Updates Jan 13
PGrid
- New scraper for PC Case Gear
- Fixed bug with gpu bulk scraper pipeline where new sources would get skipped since they have no existing cards
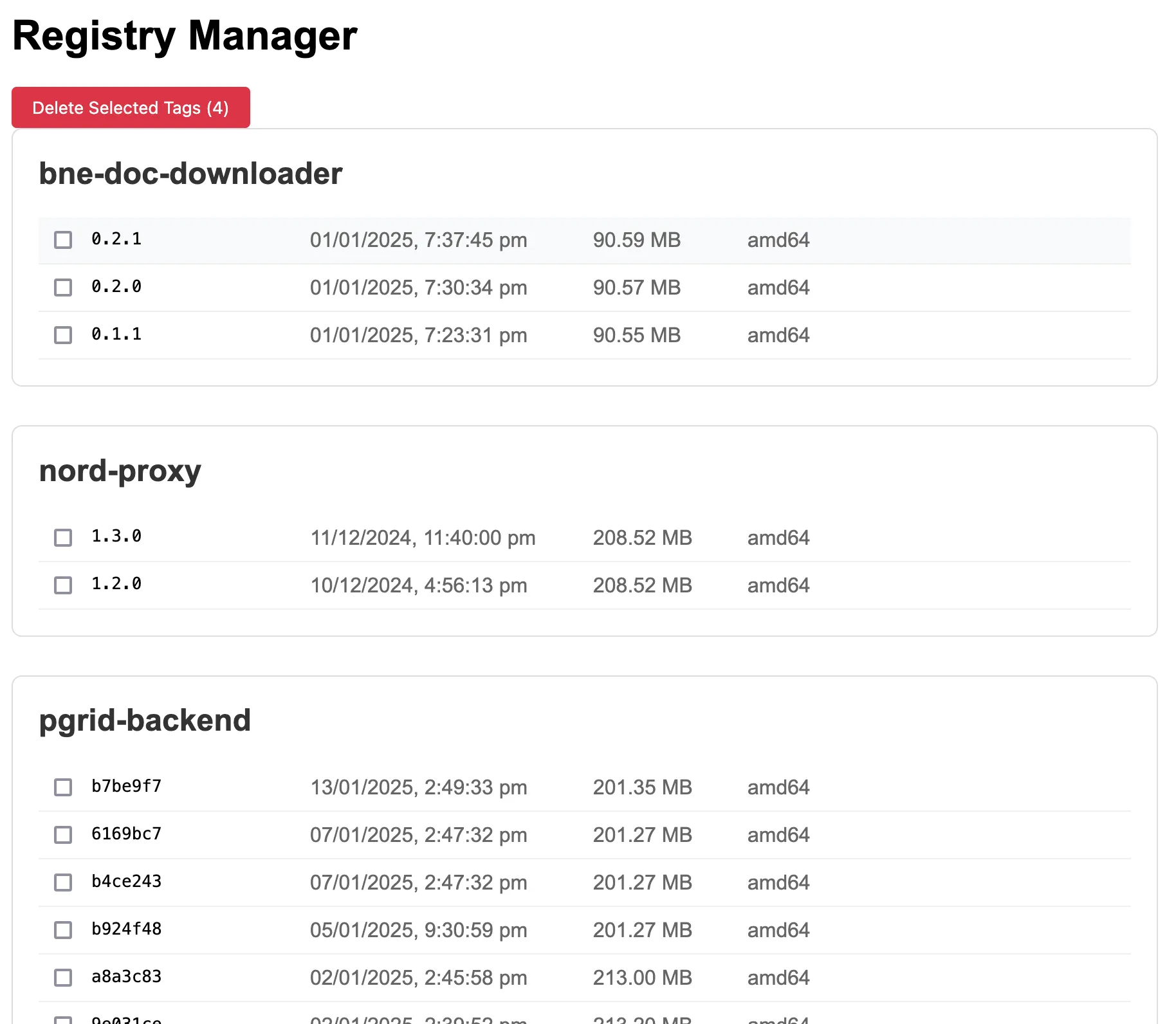
- Added a new page the manage and delete images from self hosted registry. Added a command that uses nomad to run garbage collect on registry. This ended up not working when deployed and I didn’t fix it.
- Updated Mwave scraper to be a bit more reliable and use less playwright specific functions
- Had an issue with missing layers after using the delete images frontend. Updated the build steps to use buildx which pushes layers more reliably apparently.
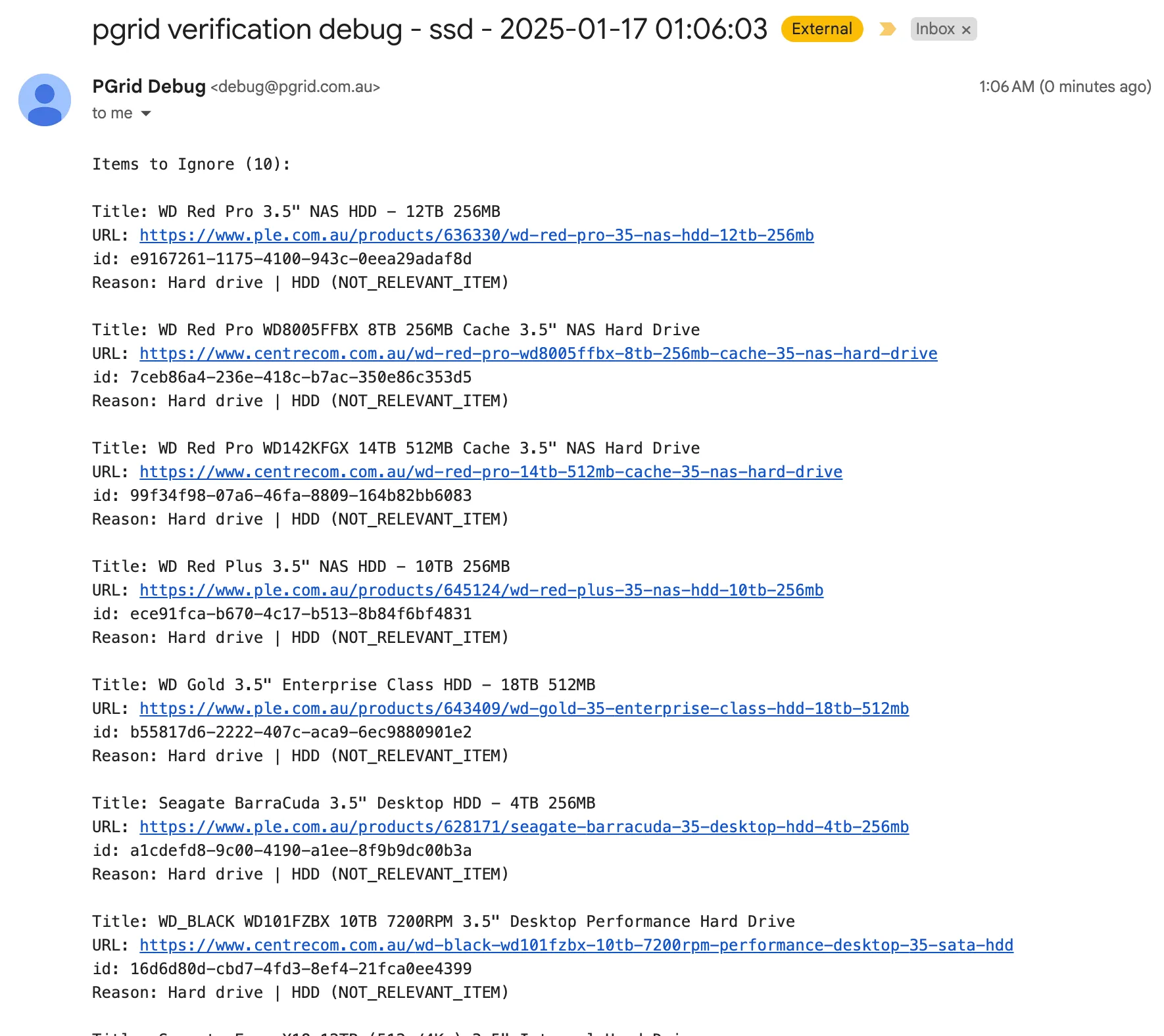
- Updated generic backend classification to have separate pre classification used for ignoring items. It works on SSDs and does batches of 100 titles in one prompt.
- Added new GPUs for 50 series including manually edited GPU page descriptions. Used Grok to generate initial description
- Due to 50 series GPUs not being available to buy but listed on 1 website, I needed to refactor to allow price snapshots with no price. This was needed for some sites where out of stock also didn’t display prices but I left out implementing as it would be a decent refactor since the model is used in a lot of places. Refactored to allow price snapshots of both gpus and generic items to not require a price.
- Lots of iteration on internal app used for classification of SSDs. Trusted AI a bit too much and the frontend of the internal app ended up being poor quality. Current implementation does 3 different searches: gemini flash with SSD csv for grounding info, gemini flash with google grounded and then pc part picker search.
- Added a grok search scraper to be used with internal classification app
- Getting all SSDs being classified was not successful this week. Wanting to get AI not just to classify titles into SSD models that I have in my database but to also populate the database with SSD models as its doing the classification. This is taking some time to get going reliably.