Updates October 20
PGrid
- Moved to using gpt5 for the reviewer llm call on model ssd classification.
- Wired up codex cli sdk to our internal openai spec server (used for perplexity searches). This allows me to use gpt5 using codex cli and not pay for it for classification.
- Continuing fixing issues with new classification architecture
- Still found it annoying using db enums created from previous classification architectures for tracking so deleted state enums for classification tracking to be replaced by typescript enums. This ended up being a very large refactor but these enums are no longer just used for tracking classification but also within the classification pipeline itself.
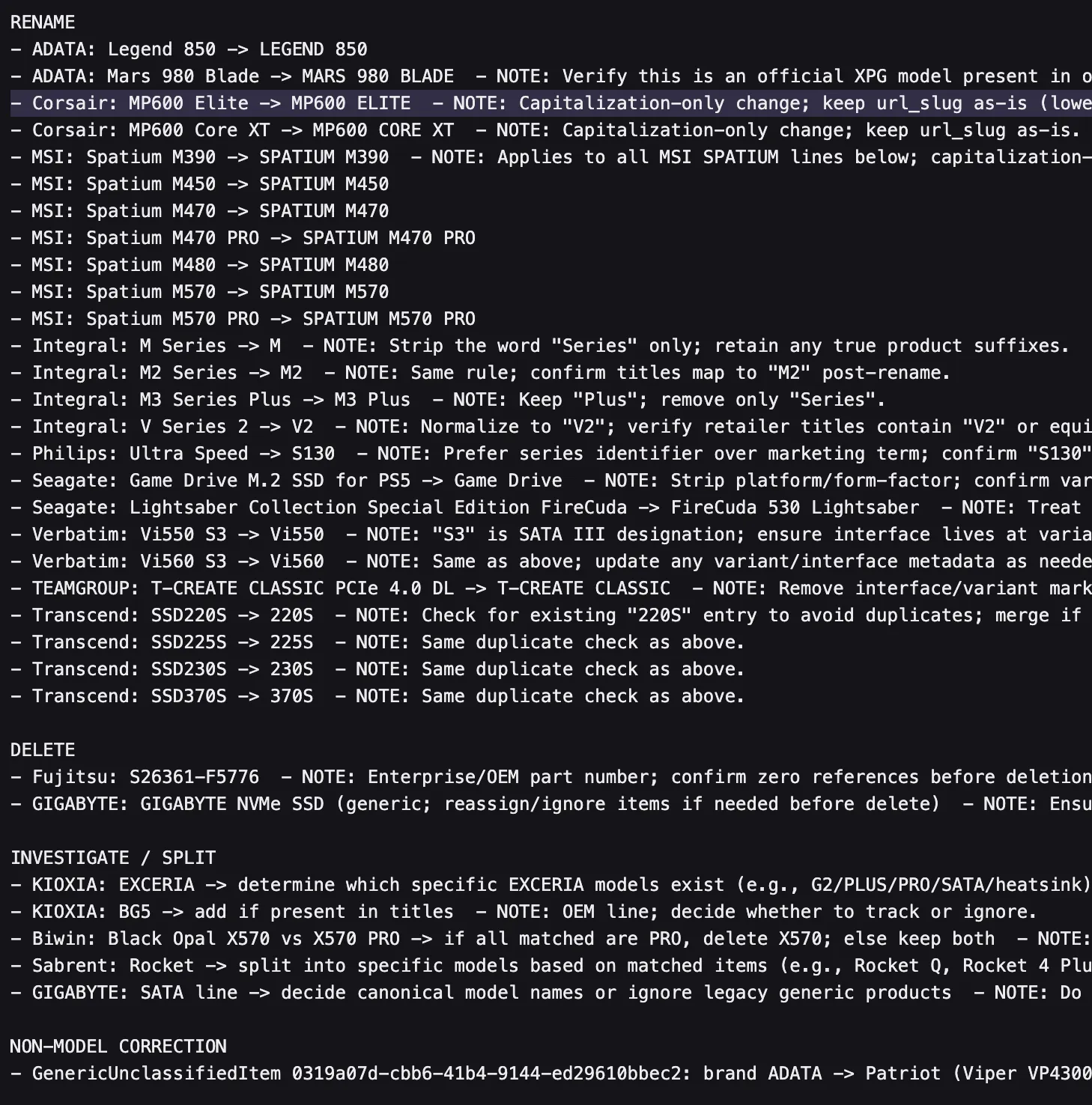
- While doing a large model stage classification run using the new architecture, it created around 200 items in the model spec search queue. This was deduped and ran creating around 70 models. But it turns out a lot of models created didn’t follow patterns in the db, or were slightly incorrect. I ended up writing and iterating on a claude code prompt that would get it to use pgrid cli and perplexity search to go through a list of models for a given brand and give suggestions on fixing model names if it found issues.
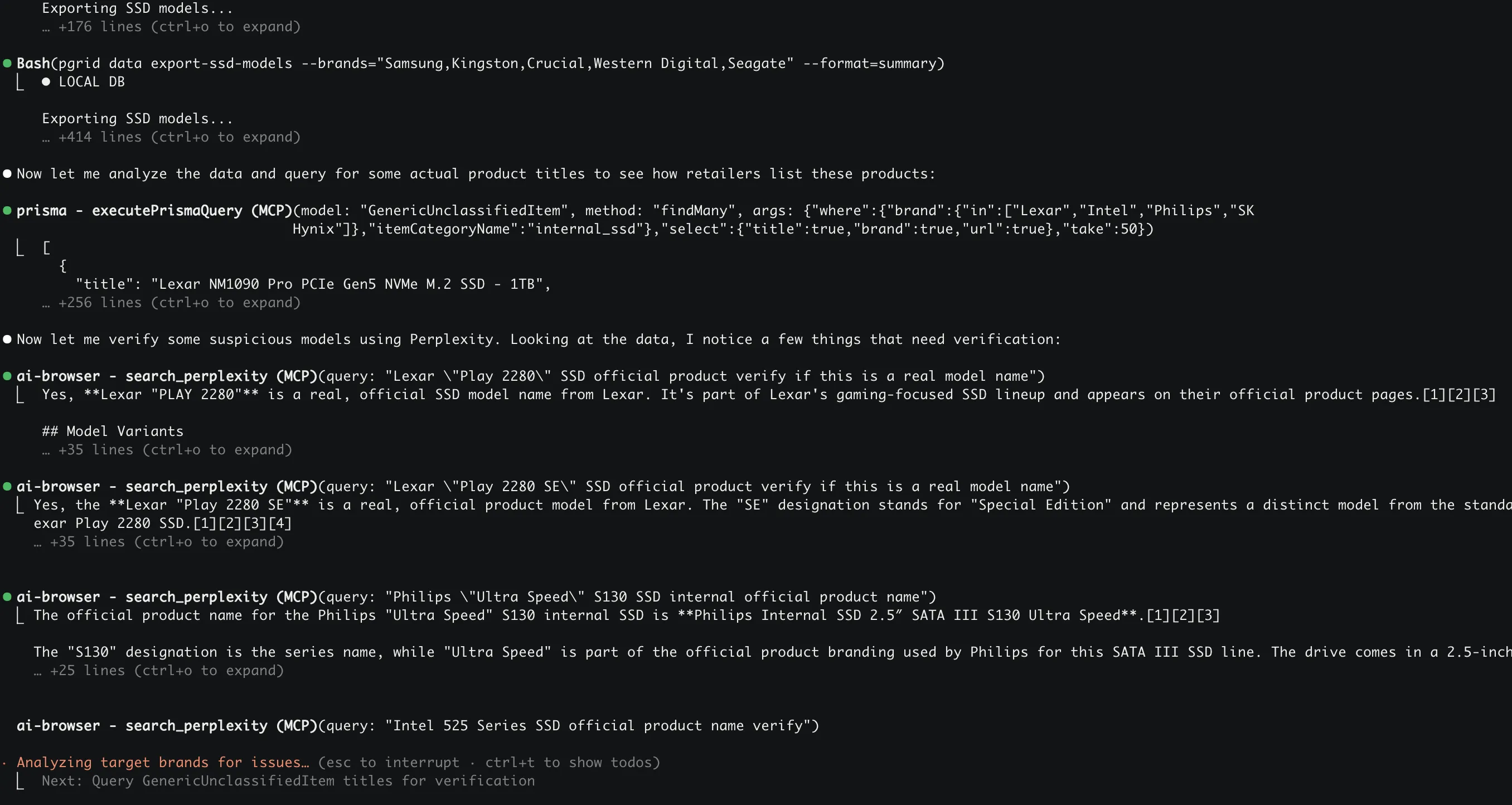
- Suggestions from running agents across all ssd models in the database. Most seemed like correct actions to take. Got another claude instance to go through and fix the ssd models in the database based on this.
- Ran model stage for ssd classification for 3100/4200 brand classified ssds. I need to move on regardless of inaccuracies I think