Updates November 3
PGrid
- Went from no LLM runs to full DB backed SSD classification with a simpler classifying system. The DB backed classification stores raw prompt input and output and parsed outputs and gives more flexibility on how things are run. Did thousands of classifications for SSDs this week.
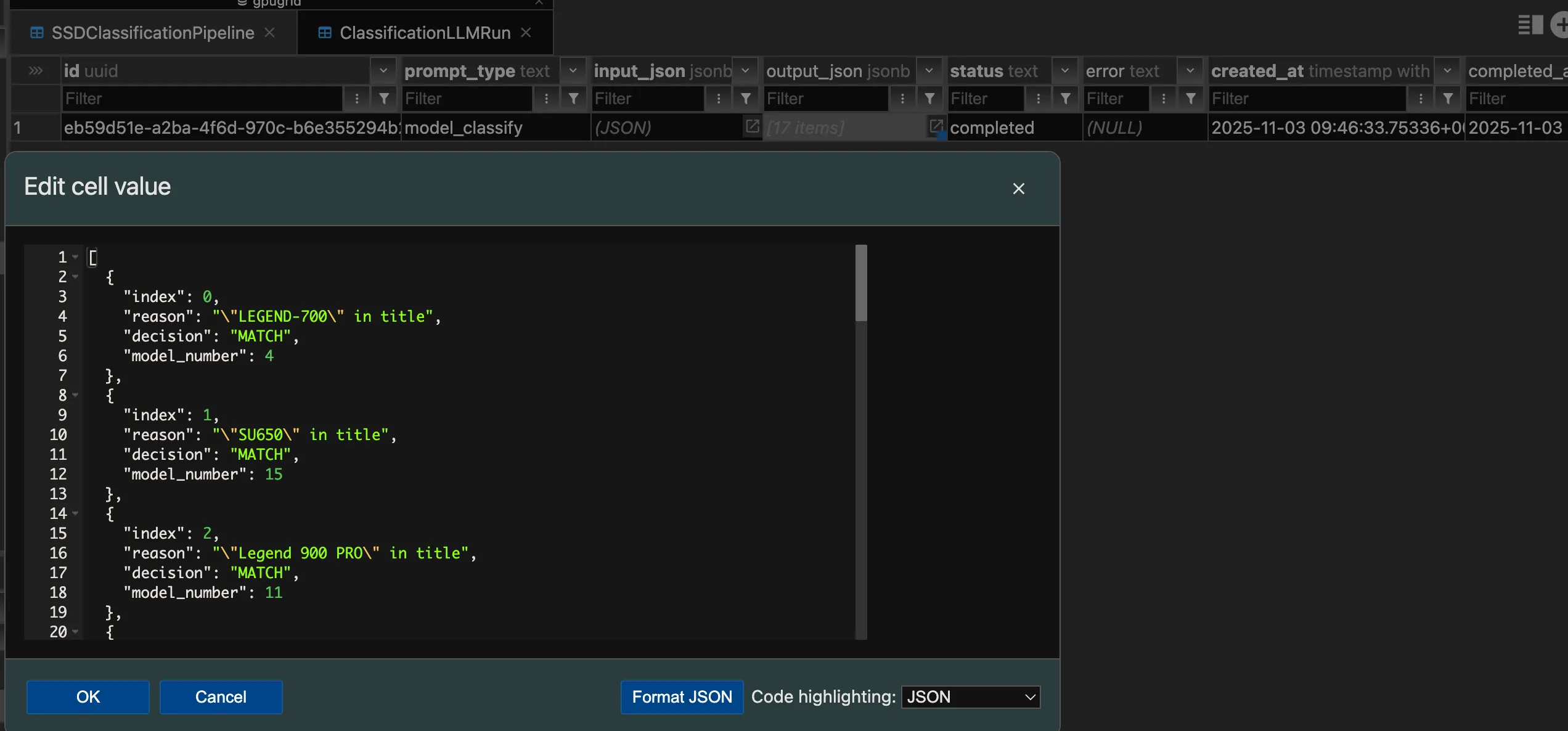
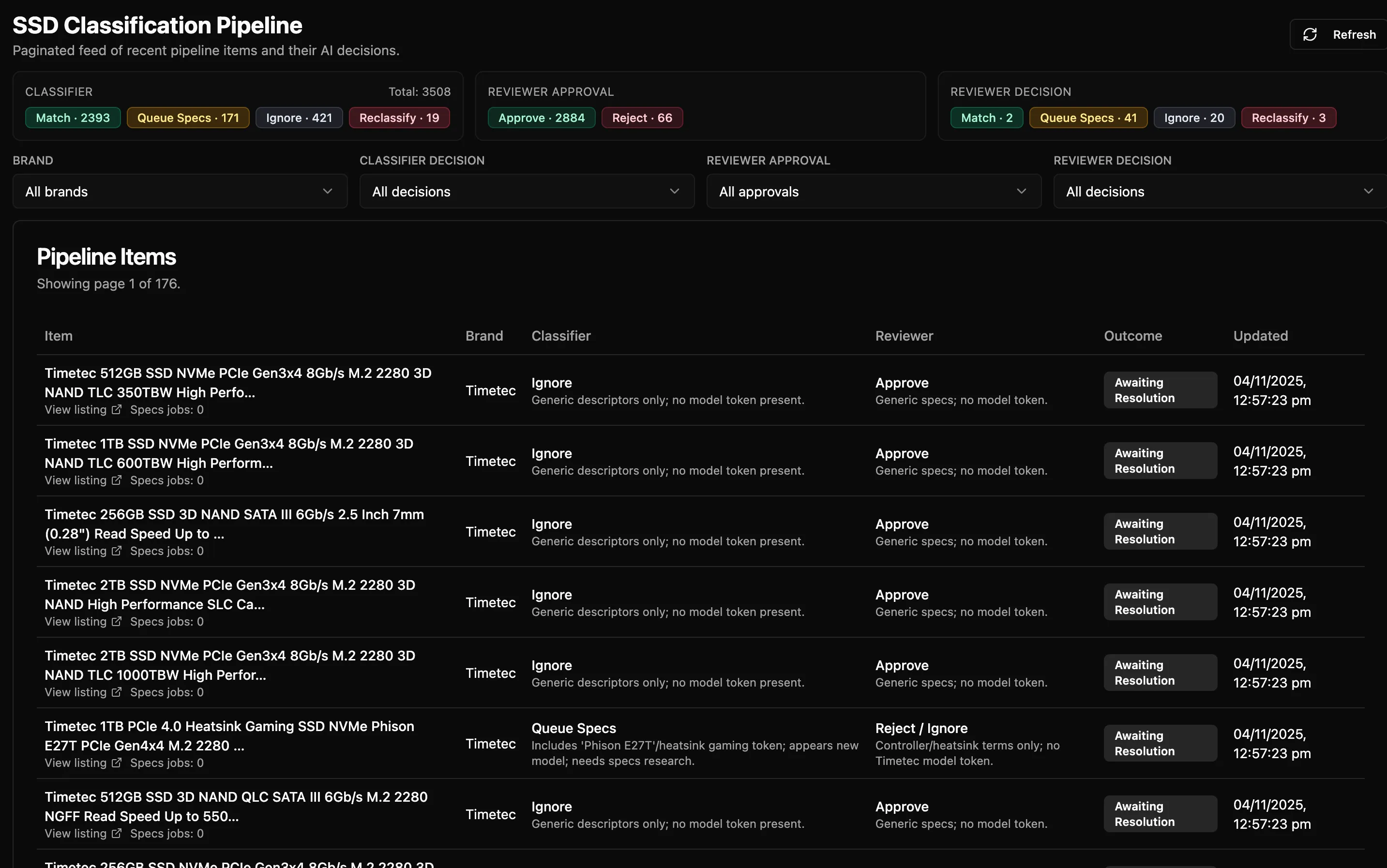
- Rewrote the classification frontend to use the DB backed classification tables. Codex was able to do almost everything by itself. This will allow deleting the tracking specific tables I think as it gives more information and requires no extra code specific to tracking things.
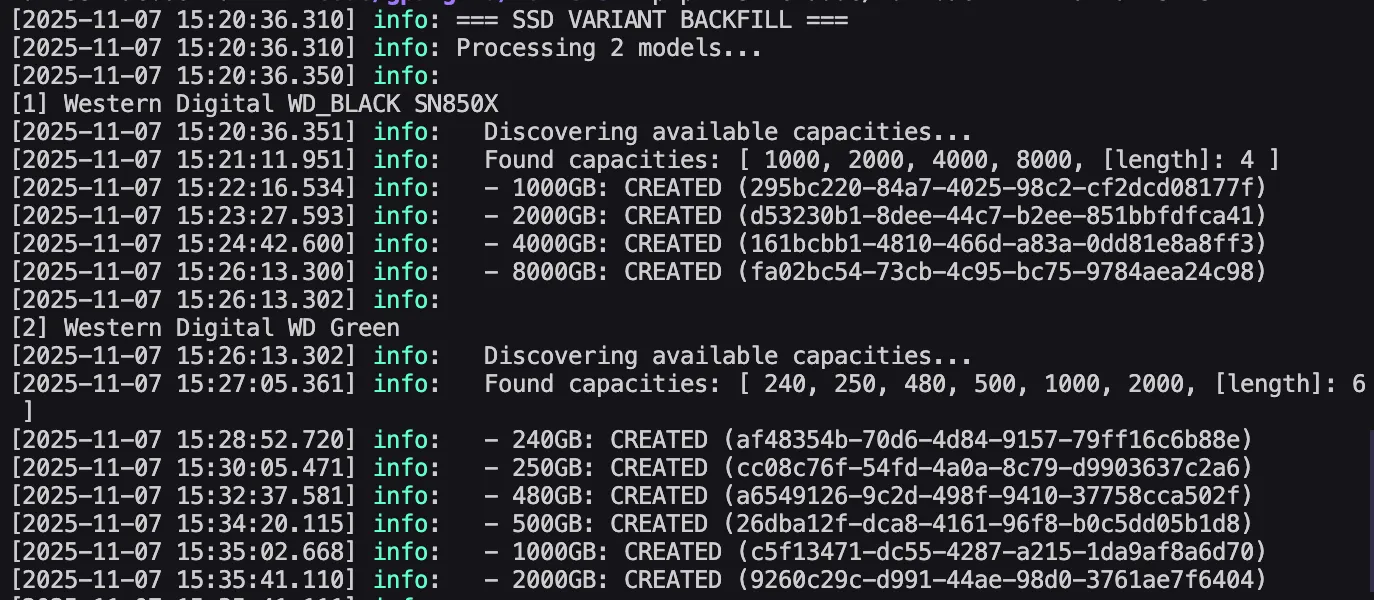
- Added a backfill script as we classify models that have missing variants. I picked the most popular models with missing variants to manually find capacities and populate variant info.
- Created CLI utility to sync local → prod all the new classification related tables.
- Deleted old manual classification tracking tables + bunch of related code.
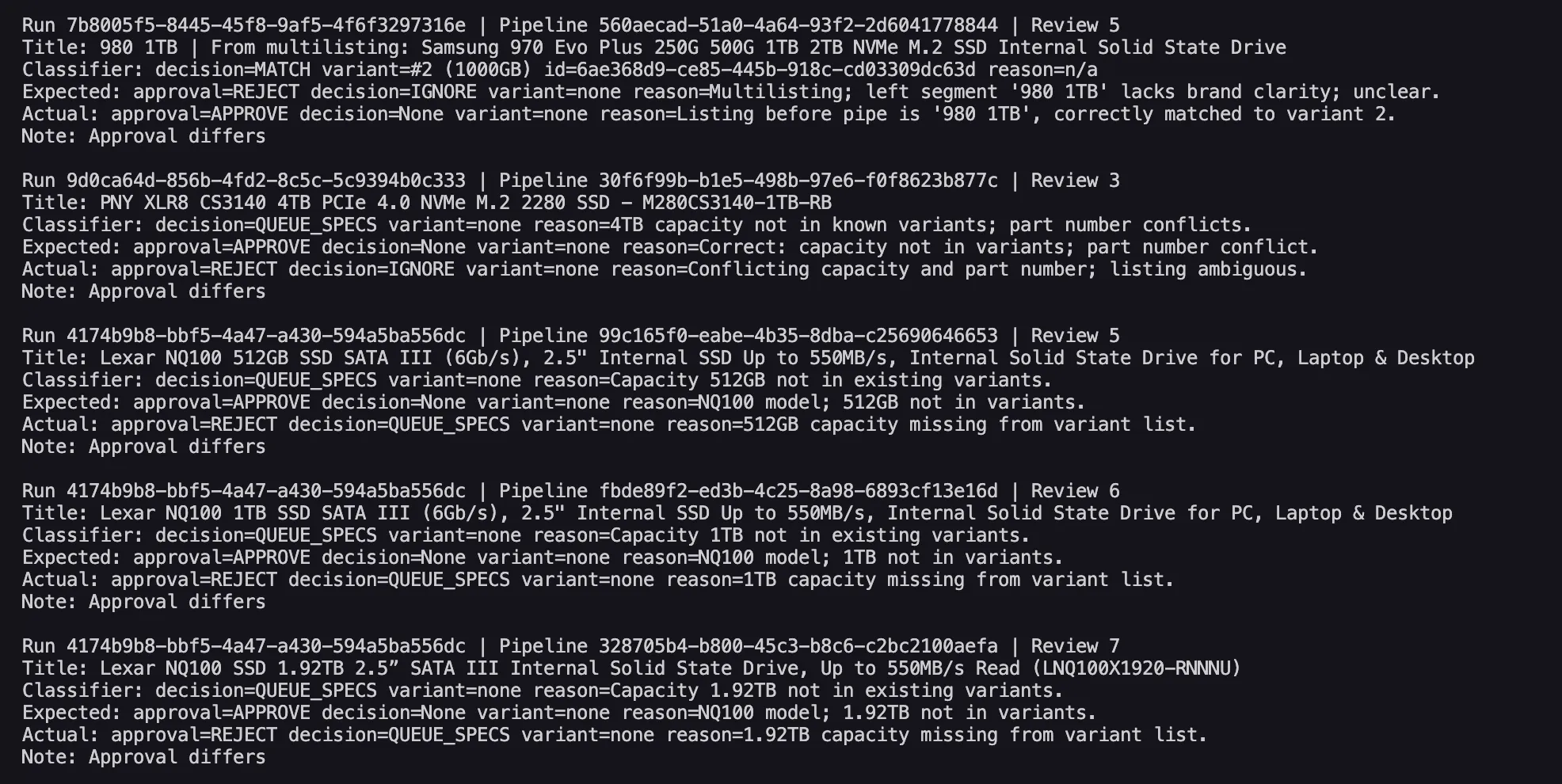
- Created script to be able to eval different models using the JSON input/outputs we store in our DB now thanks to the new structure. Finds that GPT-5 mini isn’t reliable enough to replace GPT-5 for reviewer AI.