Updates January 5
PGrid
- Working on RAM classification.
- Got up to variant classification and specs search, but it’s incomplete. RAM variants are more complicated than SSD variants (one unique attribute for SSDs vs four for RAM).
- Fixed legacy GPU-specific Amazon scraper to handle Amazon ASIN redirects.
- Added a new command in the internal dashboard to manually view and delete issue-stuck action runs. Goal is to turn this into a single-click command that gets posted to Discord when the frontend check task finds issues.
- Added item fail tracking to Grafana. Just a tweak of the existing time-series heatmaps that were used to see saved snapshots:
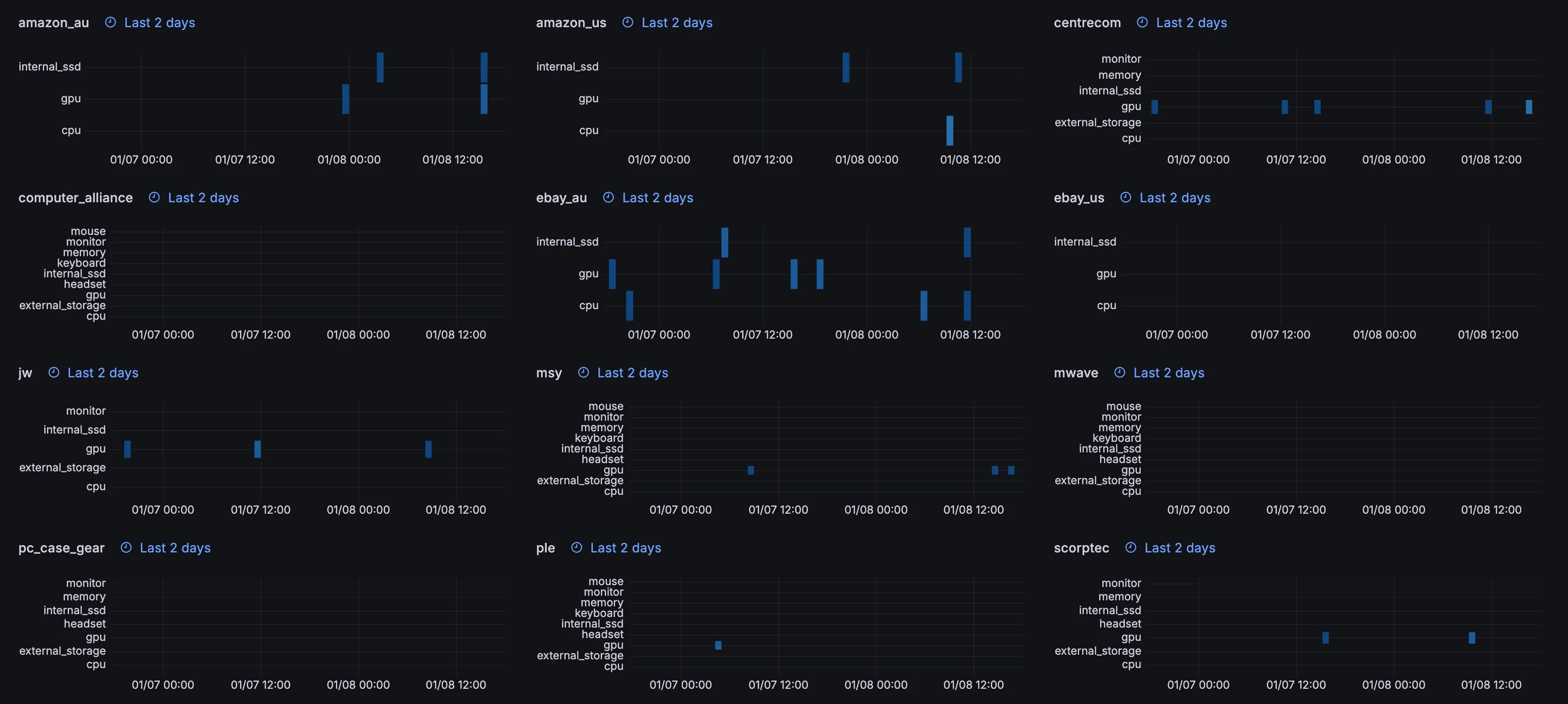
- Updated internal CLI audit function (checks whether incorrectly classified listings are being displayed) to immediately sync that data with ClickHouse.
- Added some fixes to our generic item pipeline; we now correctly fail items that are marked as no longer available. Previously we just incremented the fail count, which made it fail much slower. Also updated the pipeline to not save anything with empty titles.
- Did an SEO audit with Gemini and selected a few things to fix:
- JSON-LD wasn’t being correctly placed in our HTML, so the price range wasn’t being picked up by Google. Fixed this and added it for all categories, not just GPU.
- Added metadata breadcrumbs.
- Added international SEO data / hreflang.
- Added the ability to have custom timeouts for jobs. This was after investigating why no Amazon GPUs were being displayed, which seemed to be due to Amazon AU GPU scraping being killed after 60 minutes and nothing getting saved.
- Updated markdown rendering to include regions in its internal links. Previously it relied on the Cloudflare router to do the redirect.
- Added a cron job that runs every 10 minutes to check for deals using the new queries used in our internal CLI, which is better at finding deals than just a price-drop check.