Updates March 9
PGrid
- Further work on trying to use Gemini CLI to do classification. Added a smoke test command so I can test things more easily than running a full classification run. Tested and working on remote server. But when trying to use the Gemini CLI bridge on a real classification, I instantly ran into too many request errors. Updated classification TUI, parallel requests for Gemini CLI calls were down to 1 with a gap of 5 seconds between calls. But even that resulted in too many request errors.
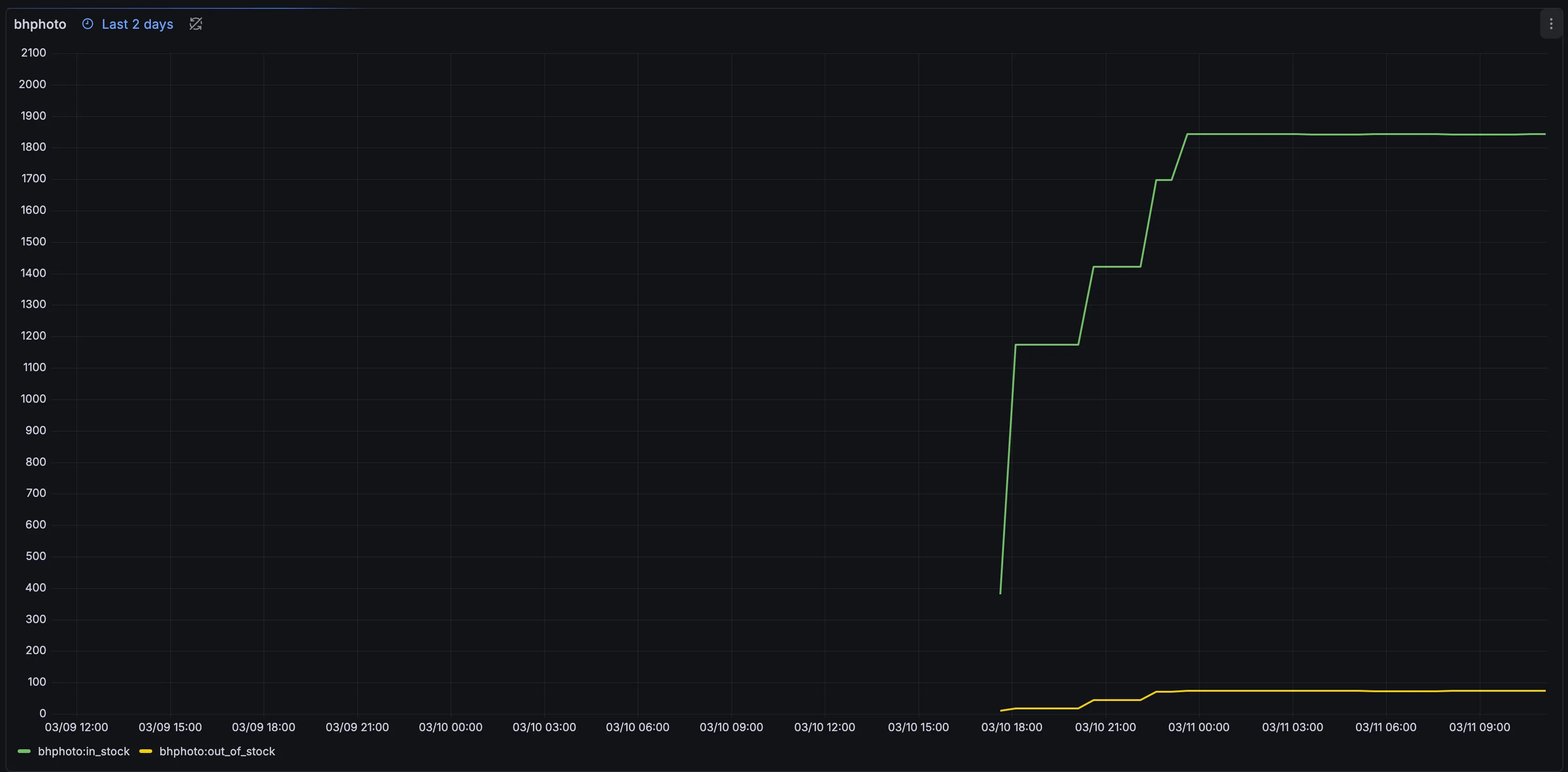
- Further work on BHPhoto scraper. There were some issues with the implementation done so far almost fully by AI. After reviewing, worked with an AI to create a skill of specific rules to follow when creating crawlers to try not to run into similar issues in the future. Enabled BHPhoto scraping for multiple categories
- Signed up for Amazon USA affiliate. Updated affiliate code to work for eBay and Amazon USA.
- Added Codex to internal CLI bridge. Allows usage of Codex CLI as an OpenAI API endpoint for classification if needed.
- Lots more work done to make a parity version of Astro and Next.js frontends. Not complete, but architecture is set up very similar to Next.js, which allows easier copy/paste style files.
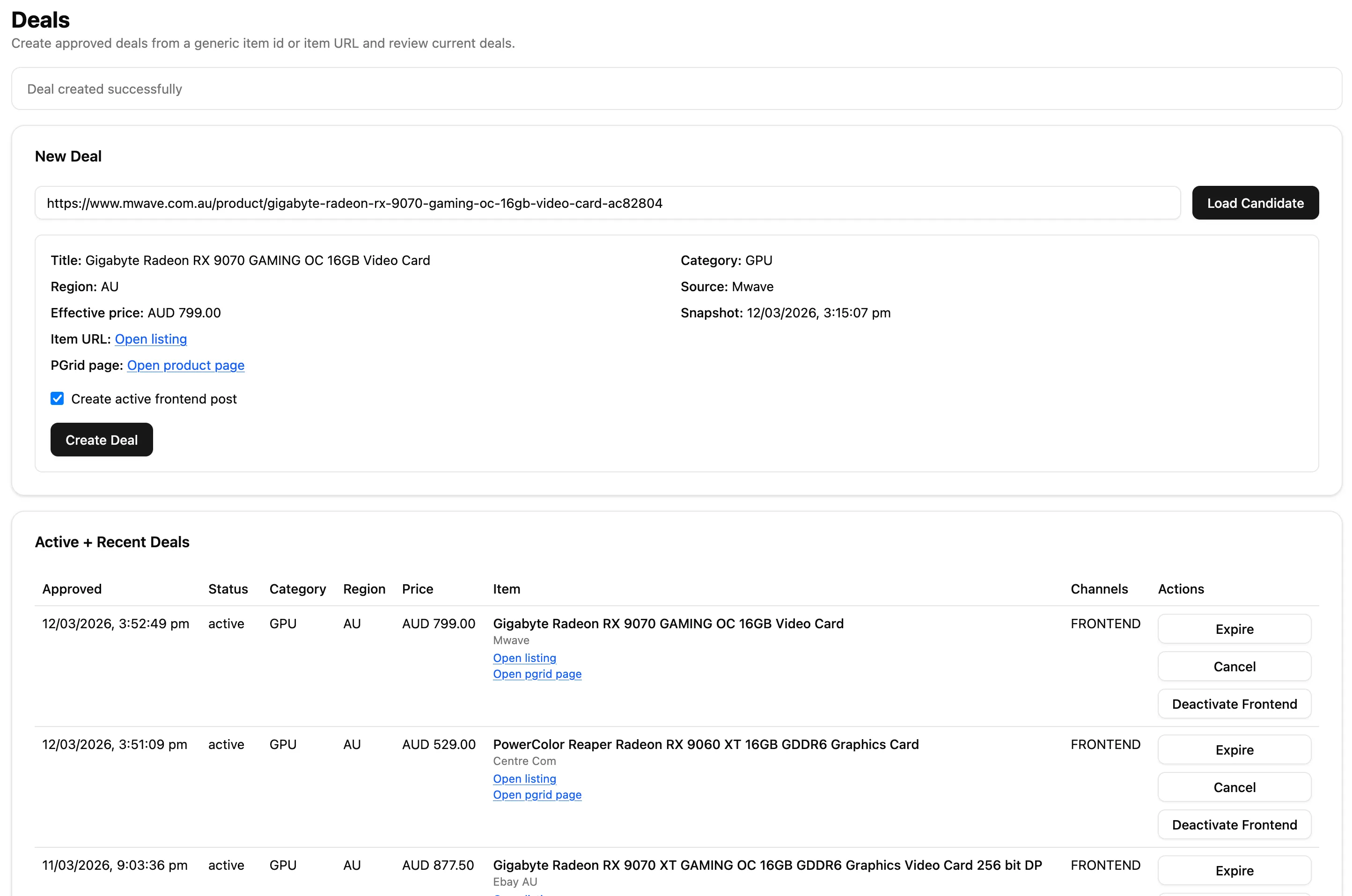
- Added a recent deals section which is manually controlled from the backend. Can be filled in from Discord alerts when prices drop for items. When there has been an active recent deal from Amazon or eBay, hourly scraping of that item is done.

- HostHatch2 server had issues and was getting DDoSed. From that, the 2 proxy instances that were running on that server were having issues. After some debugging, added a feature to be able to control MTU and set a lower value, and then things seemed to be working. Related to this refactor were a few other bug fixes with the proxy system that were encountered while deploying fixes.
- Split up eBay scraping to be more similar to Amazon. The search-based scraping now saves price snapshot information unless the listing shows that there is a coupon available. In that case, a single page scrape is done. Also, stale items not refreshed from search-based scraping are queued to be scraped individually.
- Did some evals to replace large classification LLM calls with 2 smaller ones and only save data when both small models agree. Wrote a script to do this ad hoc for all the queued items that need classification done.
- Started on JB Hi-Fi crawler.